

Right here at Ars, we have accomplished plenty of coverage of the errors and inaccuracies that LLMs usually introduce into their responses. Now, the BBC is attempting to quantify the dimensions of this confabulation drawback, a minimum of with regards to summaries of its personal information content material.
In an extensive report published this week, the BBC analyzed how 4 in style giant language fashions used or abused data from BBC articles when answering questions in regards to the information. The outcomes discovered inaccuracies, misquotes, and/or misrepresentations of BBC content material in a major proportion of the checks, supporting the information group’s conclusion that “AI assistants can not at present be relied upon to supply correct information, and so they threat deceptive the viewers.”
The place did you give you that?
To evaluate the state of AI information summaries, BBC’s Accountable AI group gathered 100 information questions associated to trending Google search subjects from the final 12 months (e.g., “What number of Russians have died in Ukraine?” or “What’s the newest on the independence referendum debate in Scotland?”). These questions have been then put to ChatGPT-4o, Microsoft Copilot Professional, Google Gemini Customary, and Perplexity, with the added instruction to “use BBC Information sources the place potential.”
The 362 responses (excluding conditions the place an LLM refused to reply) have been then reviewed by 45 BBC journalists who have been specialists on the topic in query. These journalists have been requested to search for points (both “important” or merely “some”) within the responses concerning accuracy, impartiality and editorialization, attribution, readability, context, and truthful illustration of the sourced BBC article.
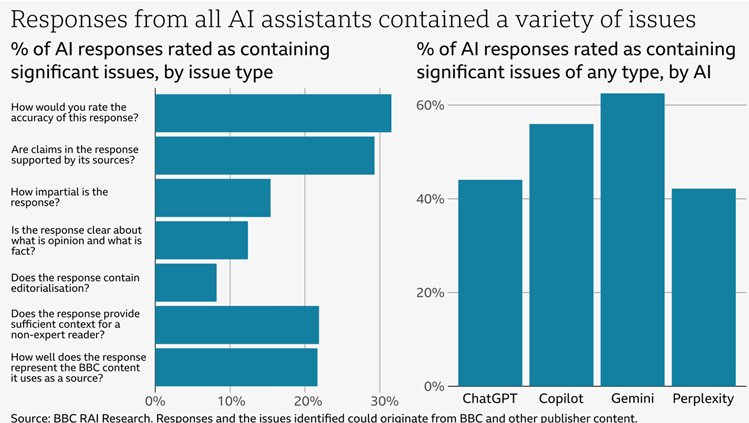
Fifty-one % of responses have been judged to have “important points” in a minimum of one among these areas, the BBC discovered. Google Gemini fared the worst total, with important points judged in simply over 60 % of responses, whereas Perplexity carried out greatest, with simply over 40 % displaying such points.
Accuracy ended up being the largest drawback throughout all 4 LLMs, with important points recognized in over 30 % of responses (with the “some points” class having considerably extra). That features one in 5 responses the place the AI response incorrectly reproduced “dates, numbers, and factual statements” that have been erroneously attributed to BBC sources. And in 13 % of circumstances the place an LLM quoted from a BBC article instantly (eight out of 62), the evaluation discovered these quotes have been “both altered from the unique supply or not current within the cited article.”